
Hi Guys! In this blog, I am going to share my understanding of PatchGAN (only), how are they different from normal CNN Networks, and how to conclude input patch size with a given architecture. If you are familiar with Convolutional Neural Network (CNN) and Generative Adversarial Network (GAN) — briefly, then you are good to go.
GAN briefly about with good analagous example…
(To read more details, kindly click on GAN link where I’ve provided you the research paper pdf.)In the adversarial nets framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency. Competition in this game drives both teams to improve their methods until the counterfeits are indistinguishable from the genuine articles.
Remember: Generative Model and Discriminative Model architecture can be different (like either used Deep Learning Models or any Machine Learning Models). They are independent to each other with their own objective to accomplish.
Reading and Analysing for a period…
While I was reading this paper, ‘Image-to-Image Translation with Conditional Adversarial Networks’ and ‘Unpaired image-to-image Translation using Cycle-Consistent Adversarial Networks’, **PatchGAN Model was used in discriminator model**. That where I stuck here and unable to move forward.
I wasn’t able to understand what PatchGAN was and how it was working behind intuitively and how it was different from the CNN network. Someone asked in the Github profile about this case and the author of this paper replied:
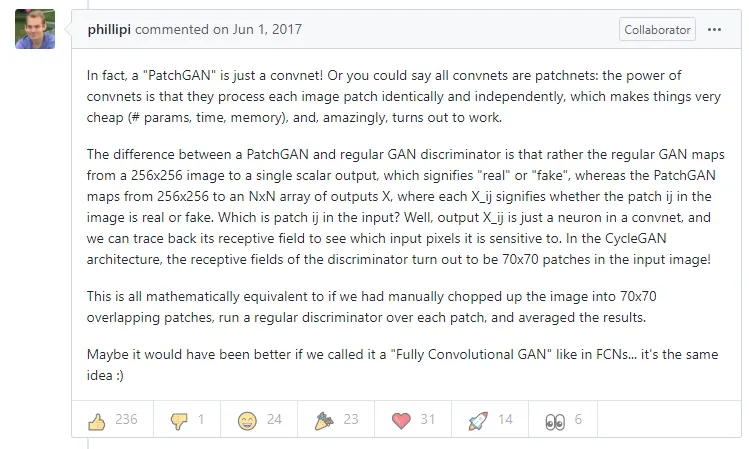
Now we understood the difference between PatchGAN and CNN:
CNN, after feeding one input image to the network, gives you the probabilities of a whole input image size that they belong in the scalar vector.
However, In PatchGAN, after feeding one input image to the network, it gives you the probabilities of two things: either real or fake, but not in scalar output indeed, it used the NxN output vector. Here NxN can be different depending on the dimension of an input image (I will show you the result later in Code section) but each output vector represents 70x70 patches/portion of an input image (not whole input size) and this is fixed because that how architecture is made of.
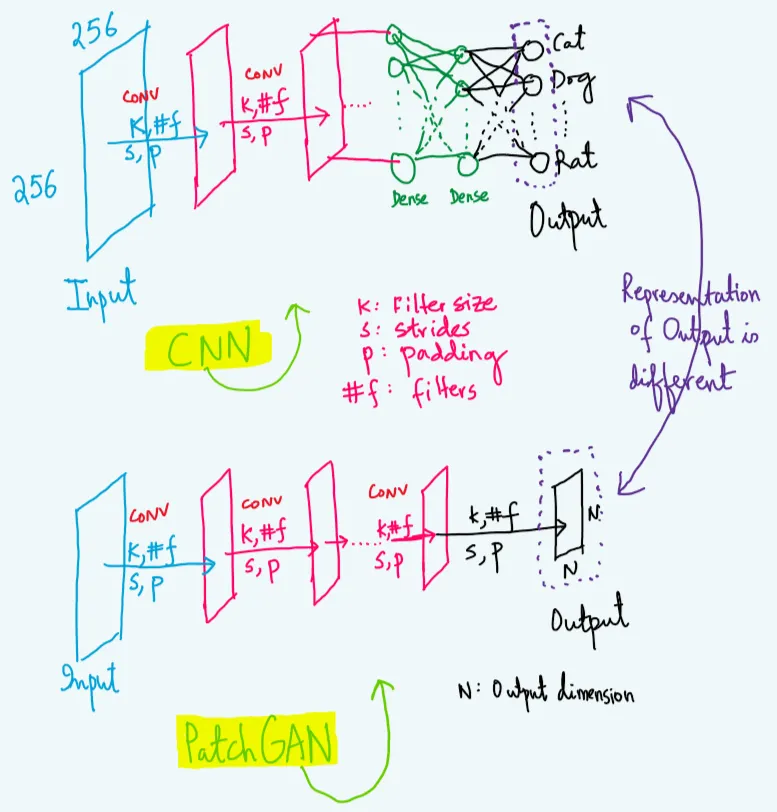
Remember: I just drawn the figure in the simplified diagram (I neglected the number of filters which make 3D diagram) to get better understanding in the upcoming reading.
But…
Here I didn’t get how each output vector corresponds to 70x70 input patches (Although the author did mention he used traceback by mathematically). So, I will be going to illustrate in this blog how we got 70x70 patches of these inputs.
The input image dimension can be anything, let say, 256x256 dimensions. The architecture of PatchGAN is:

Again, here also I neglect the number of filters to draw 3D diagram but I mentioned the number of filters used so that you can implement by seeking this architecture. Its all does is increase the dimensions to give more information. But here I am going to tell you how 70x70 patch of an input is obtained. So, it doesn’t affect with number of filters, everything is same. You can try it out later.
All you need to remember is the number of filters, kernel size, strides, and padding values in each layer. (This is fixed).
For implementation point of view, for the first three Convolution layers (i.e. I →C1 →C2 →C3), set padding=’ same’ and from the next two Convolution layers (i.e. C3 →C4 →O), set padding=’ valid’ and also we perform Zero Padding in C3 and C4 layer only. (So, performing convolution operation in the C3 layer, make sure zero paddings are done beforehand because we set padding=’ valid’ in architecture. Similarly the same for the C4 layer also.)
Of course! You can take different parameter values also and do playground and experiments to see whether it works better than this architecture or not. Till now, this PatchGAN architecture with these parameters working better ones.
If you are familiar with CNN…
If you are aware of how the size of the next layer or output layer change concerning given kernel size, padding, and strides in CNN, it calculated as (with considering example in Figure 2. from Input I to Next layer C1)

Similarly with applying this formula to all layers in Fig 2., you will get the final output 30x30 dimensions.
Backtracking…
Now, let us understand about backtracking to know the region (or portion or more concise — receptive field). For that, we will start
1. Backtrace from the output layer ‘O’ to the ‘C4’ layer.
Let take with one-pixel output for simplicity. Once you understood in the end, you can analyze multiple pixels also.

Take your time for understanding step 2 in the above figure. Once you understood, the next step will be the same related to this concept.
Now, we got the receptive field size of the C4 layer for a particular one-pixel output layer O.
2. Backtrace from the ‘C4’ layer to the ‘C3’ layer.

Since the number of pixels in the column is equal to the number of pixels in rows, the outcome will be the same, which is a 7x7 receptive field for the C3 layer.
Remember if you are aware of how strides work on CNN then you able to understand. That why I told you beforehand, you must know how padding, strides works behind intuively.
After analyzing from this figure, we got the tricky formula for this:

Just apply this formula. For examples as follows:

Since we got a 4x4 receptive field of C4 layer (that what should we expected. See Figure 4. what was the receptive field for the C4 layer?). Let move to the previous layer i.e from the C4 layer to the C3 layer.

Woohoo! That has to be expected. See Figure 5. what was the receptive field for C3 Layer?.
Lastly, let check whether this formula is correctly verified or not?

Great! See Figure 4., what was the size of the C3 layer before performing the convolution operation?
So, either way.
Either you visualize by taking a pen/pencil and draw step by step like I did to show the illustration in Figure 4 and Figure 5
OR
You can observe with the formula based I got.
From the C3 layer to the C2 layer and so on, it will be hard to draw and illustrate a 7x7 pixel, to begin with. So, you can take a pen/pencil and draw it into your paper and try to illustrate it. I am following with the formula based…
3. Backtracing using Formula
So, let start from the begin backtrace to all layers step by step (O →C4 →C3 →C2 →C1 →I).
Remember I have calculated separate as ‘r’ indicate row pixels and ‘c’ indicate column pixels. the resultant would be like (r x c)
For example in this case below, separate expression on r and c:
r: (4) + (1)(1–1) = 4
c: (4) + (1)(1–1) = 4
(r x c) = (4 x 4) receptive field of previous layer of O i.e. C4 layer.





So, here we got it. For every single pixel from the O layer, it’s only considered a 70x70 patches/portion of the all images input layer I.
Finally…
So, In Tensorflow Pix2Pix, there is also mentioned there about what is PatchGAN

So, the question was how 70x70 portion of input image calculated with given 30x30 output and right now, we understood how it got there.
Code
Remember: I have not added like BatchNormalization, Dropout, etc. This blog only means to understand how 70x70 portion of an input is obtained from input images.

In Fig 6., see the output patch in both with different input shapes. We just showed you the same example for the left part (i.e. 30x30).
Similarly, you can evaluate for the right part (i.e. 14x14). You will find that this also takes a 70x70 portion of input images, So, this architecture is fixed and designed in such that way!.
I hope, you got it about what PatchGAN is.
Thanks for reading my blog! Have a great day :D
(Here my Linkedin Profile )
